
Nevod entity recognition is 30 times faster than Microsoft Recognizers Text
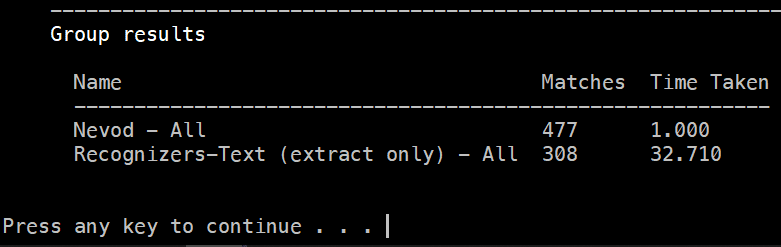
Nevod pattern-based entity recognition with zero coding is 30 times faster than Microsoft Recognizers Text, while having 98% compatibility according to unit tests.
Microsoft Recognizers Text
Microsoft Recognizers Text is a library for recognition and resolution of text entities like numbers, units, date/time, etc. The library is based on regular expressions and hand-coded algorithmic postprocessing. It is able to recognize date/time, numbers, URLs, emails, phone numbers and more. For date/time entities, it provides resolution - conversion of matched phrases in input text into programming language “date-time” object. Microsoft Recognizers Text is used in such services as LUIS: Language Understanding Intelligent Service, Microsoft Bot Framework and Text Analytics Cognitive Service.
While having good accuracy and multiple languages support, Microsoft Recognizers Text has poor performance on text articles with more than 100-200 words, for example in our test set of 20 articles with the total size of 230k characters it takes 0.5 second to process a single file in a single language (English) and recognize common entities in it (see Nevod section for comparison details). The reason of such performance is that Microsoft Recognizers Text uses sets of regular expressions which are sequentially applied to input text. In some cases, results produced by regular expressions are then processed by other regular expressions in combination with algorithmic postprocessing. This pipeline acts as a black box and, while producing high quality results, it is difficult to use it as part of a custom solutions due to poor performance and lack of tuning.
Nevod
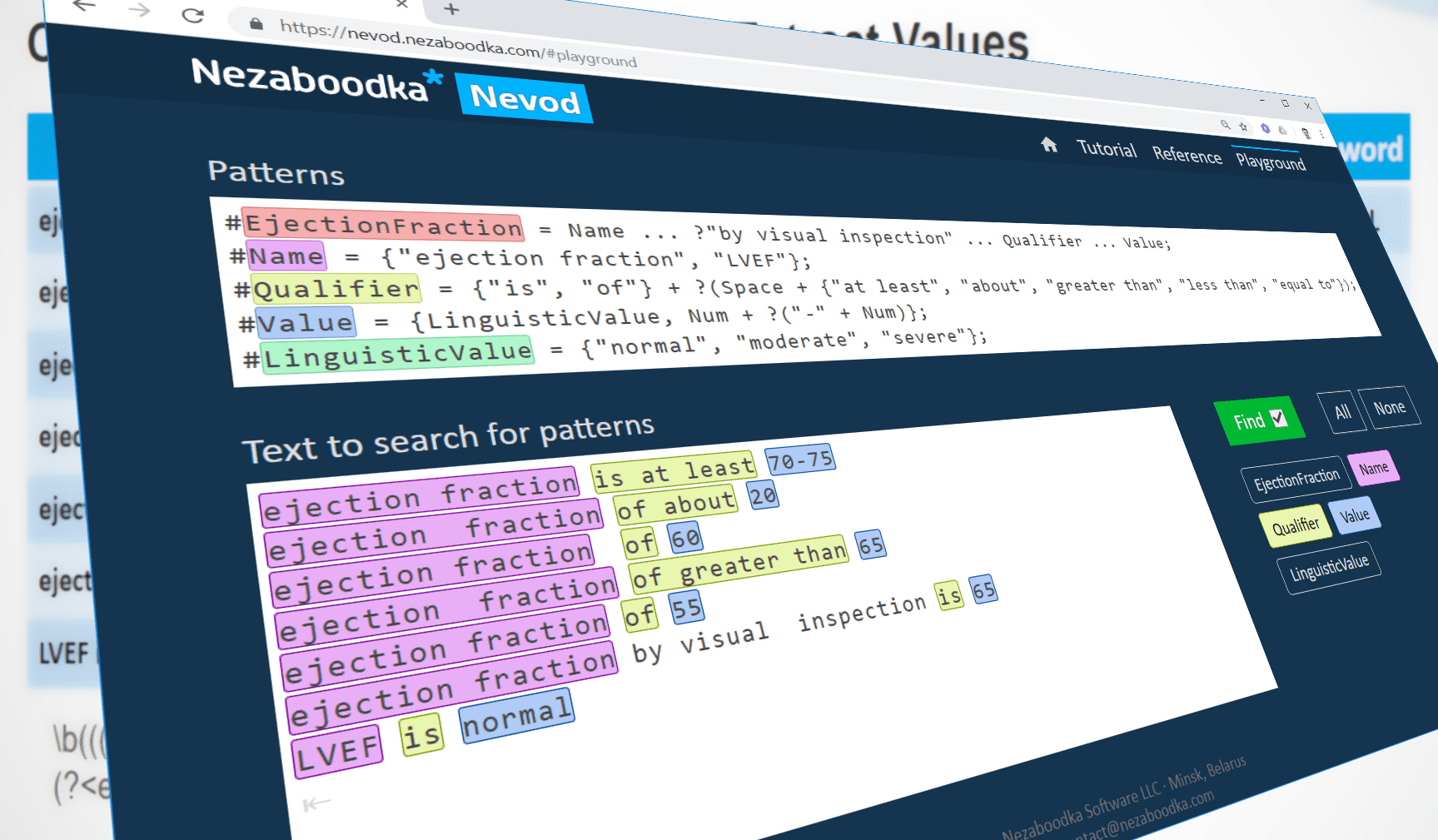
We have taken test cases specs, provided in Microsoft Recognizers Text library, to develop Nevod patterns that combine the results of Microsoft Recognizers Text with the advantage of Nevod declarative patterns (that require no program coding) and high performance. Nevod pattern recognition was compared solely to text extraction functionality of Microsoft Recognizers Text. The resolution of entities (conversion of text fragments into programming language objects) was excluded from comparison.
In total, 98% pass rate was achieved for the following entities: date, time, date and time, URL, email, IP address, phone number, GUID, #hashtag and @mention:

Performance was measured against test set of 20 news articles with the total size of 230k characters:

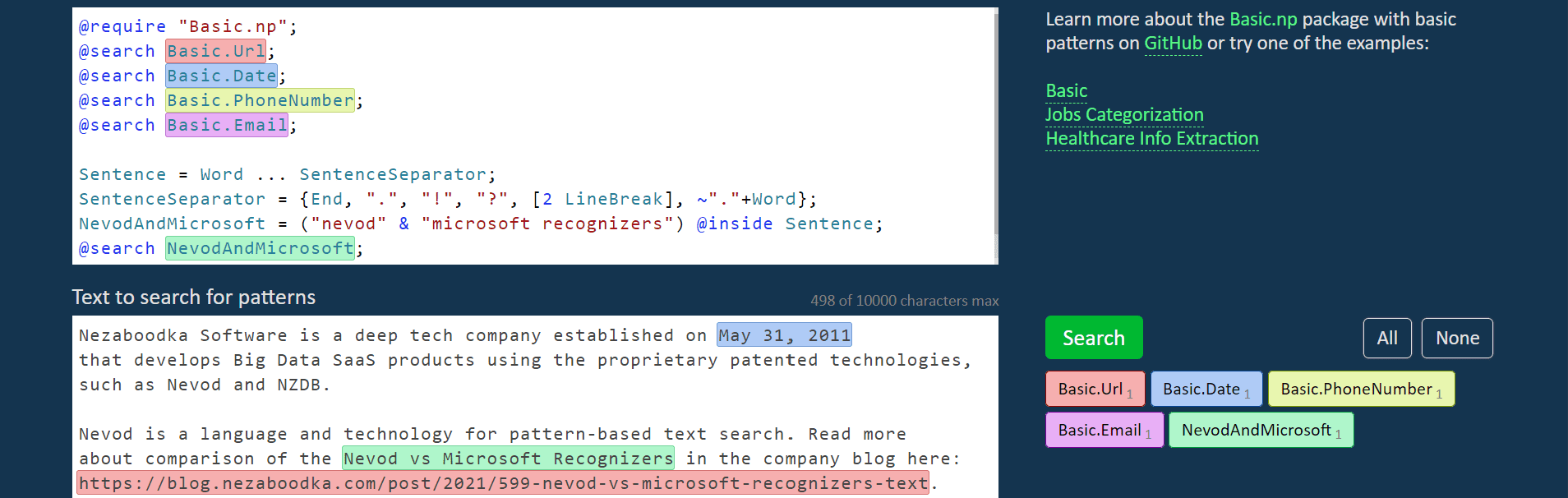
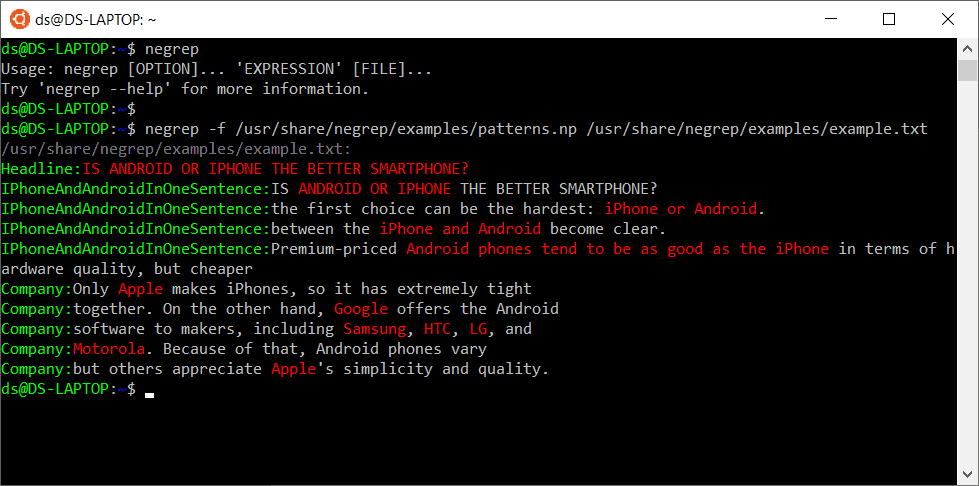
You can try Nevod patterns for recognition of text entities yourself in the Nevod playground or via running the free negrep utility on your local computer.