Nevod: Technology for Pattern-Based Natural Language Processing
Nowadays, more and more software applications require integration of the text analysis functionality.
Text data come to applications from various sources, such as databases, document storages, web pages, news, blog posts, emails, chats of instant messengers, voice transcripts of call centers, video subtitles, books, etc. The vast majority of text data are in natural language.
Text analysis is typically aimed at understanding of the text subject area and recognition of various entities, relationships and sentiments, to later allow semantic search for recognized companies, people, events, products, topics, emotions, phone numbers, emails, links, etc. over all collected text data.
Text analysis is not an easy task, mostly because text in natural language is unstructured, ambiguous and difficult for machine processing.
Approaches for text analysis vary in nature, but the mostly used ones can be grouped into the following three classes:
- Keyword-based full-text search;
- Pattern-based text analysis, e.g. regular expressions (RegExp);
- Natural language understanding (NLU) based on neural networks (AI) and machine learning.
Keyword-based full-text search is very fast and highly scalable, but is inappropriate for recognition of entities and relationships.
NLU allows recognition of entities and relationships, but is slow, poorly scaled and its results cannot be explained and understood by user. This approach is also hard to fine-tune: you need to retrain the entire neural network, which becomes better on one data, but worse on another data.
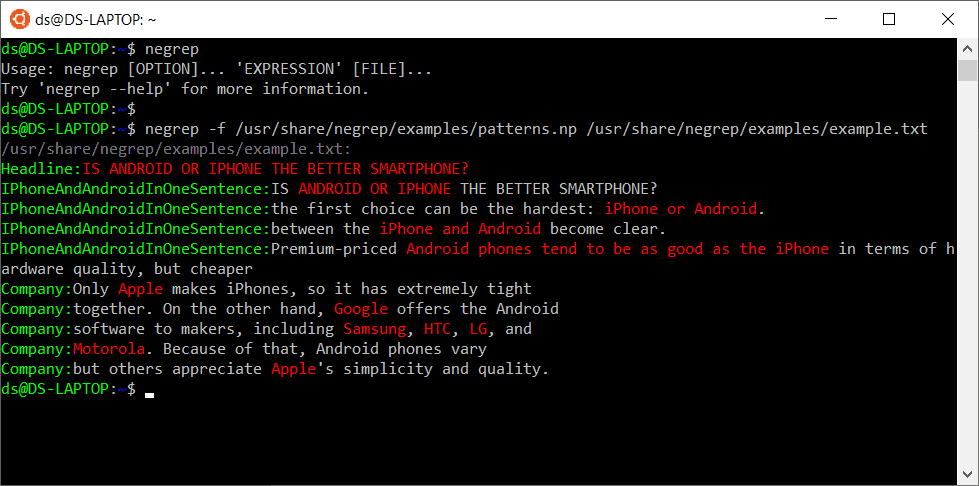
Pattern-based text analysis, on the contrary, may combine advantages of the keyword-based search and NLU, however, there are almost no implementations that are language neutral, easy to use and fast. Many of the implementations are based on regular expressions, which are not easy to read, don’t allow references to other patterns, and are matched one-by-one, so the speed degrades linearly when you add patterns.
Meanwhile, there is an emerging patent-pending technology that is being developed at Nezaboodka and called Nevod, which outperforms all the above approaches in performance, scalability, flexibility, and recognition quality.
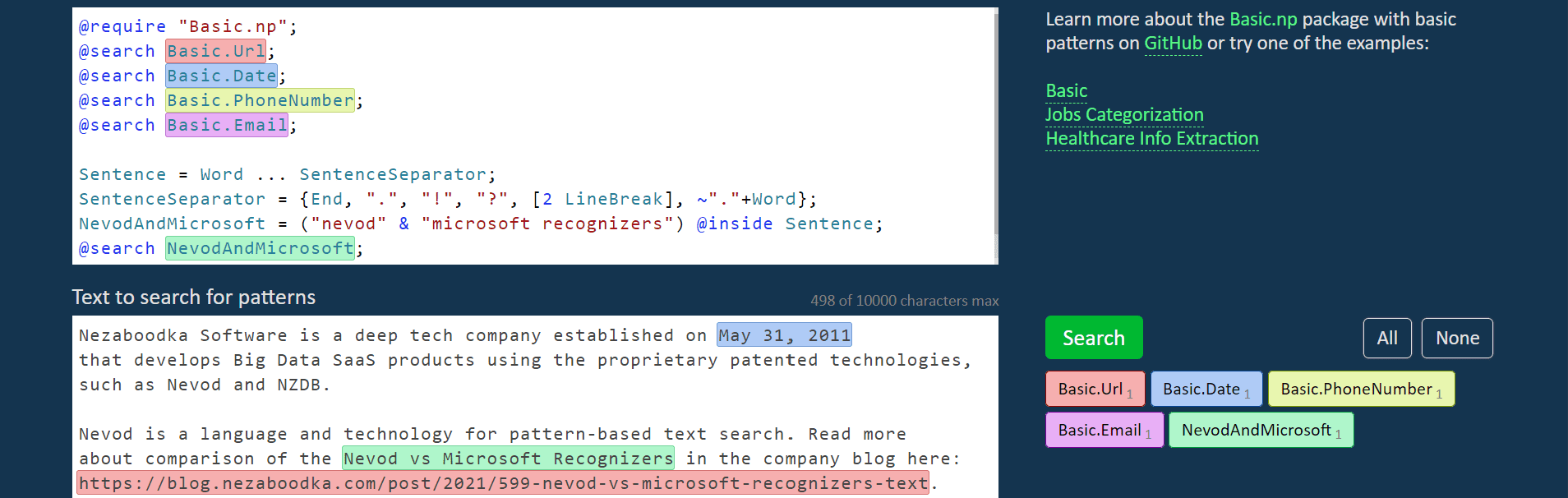
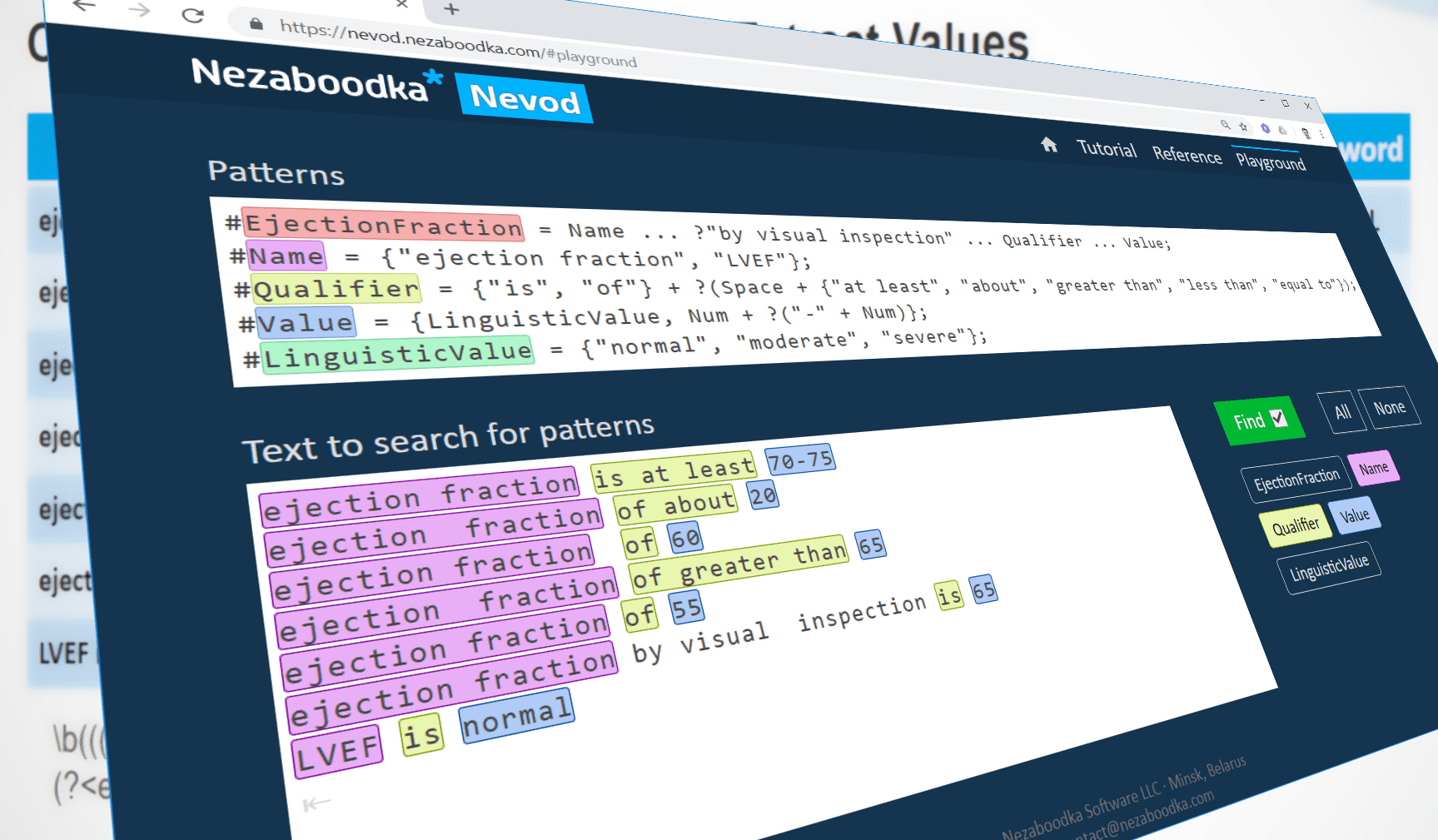
Nevod is a language and pattern-based technology specially aimed to rapidly reveal entities and their relationships in texts written in the natural language. Here are main features and differentiators of it:
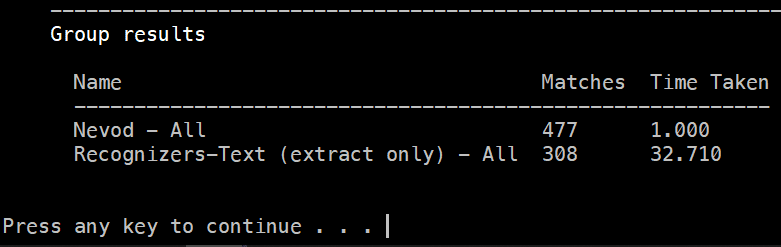
- Hundreds of times faster than RegExp on a rule deck of 1K patterns;
- Designed for regular users, not only for programmers;
- Operates on words, not individual characters;
- Matches all patterns in one pass;
- Allows recursive patterns;
- Language neutral;
- Safe and scalable to use in the Internet;
- Allows creation, reuse and sharing of pattern libraries.
You can try it yourself in the publicly available Nevod playground. Start from reading tutorial and language reference.