
Using Nevod for Text Analytics in Healthcare
In certain cases, the pattern-based text analysis is the only option for automatic processing of clinical data in healthcare.
“Eighty percent of clinical data is locked away in unstructured physician notes that can’t be read by an EHR (electronic health record) and so can’t be accessed by advanced decision support and quality improvement applications,” according to Peter J. Embi, MD, MS, President and CEO of Regenstrief Institute.
“More than 95 percent of health systems can’t utilize this valuable clinical data because the analytics needed to access it is difficult, expensive, and requires an advanced technical skillset and infrastructure,” — emphasizes Eric Just, Health Catalyst SVP of Product Development.
There is an article describing the case when integration of text analytics led to the increase of more than triple the number found patients with PAD (peripheral arterial disease) compared to using traditional methods that are limited to codified diagnoses and procedures in structured EMR (electronic medical records). Such result was achieved by leveraging text search enhanced with NLP over unstructured text data.
The proposed approach to text analytics is based on creation of NLP pipeline, which includes text search by keywords, sentence detection, entity recognition (i.e. diabetes), applying context algorithm, as well as presenting results to user with additional filtering.
The article provides an indicative example of extraction values of certain measures from text, e.g. the measure of ejection fraction, which is not stored as discrete values. This is illustrated by the following picture:

Below the table you see the regular expression (RegExp) used to find and extract numeric and linguistic values of the “ejection fraction” measure like “60”, “70-75”, “normal” together with qualifiers like “is at least”, “of about”, “is”, etc.
Let us look at this RegExp once again:
\b(((LV)?EF)|(Ejection\s+Fraction))\s+
(?<qualifiers>([^\s\d]+\s+){0,5})
\(?(((?<ef_low>\d+)-(?<ef_high>\d+))|(?<ef_mid_txt>\d+)|
(?<ef_word>([^\s]*?normal)|(moderate)|(severe)))Well, how much time do you need to understand this crypto text? Now think of how much time you will need to adjust this RegExp to make it find ejection fraction in the text like “ejection fraction by visual inspection is normal”. You will agree that RegExp is not easy to write, very hard to read, and almost impossible to maintain.
Now let us take the Nevod technology and use it for the same purpose.
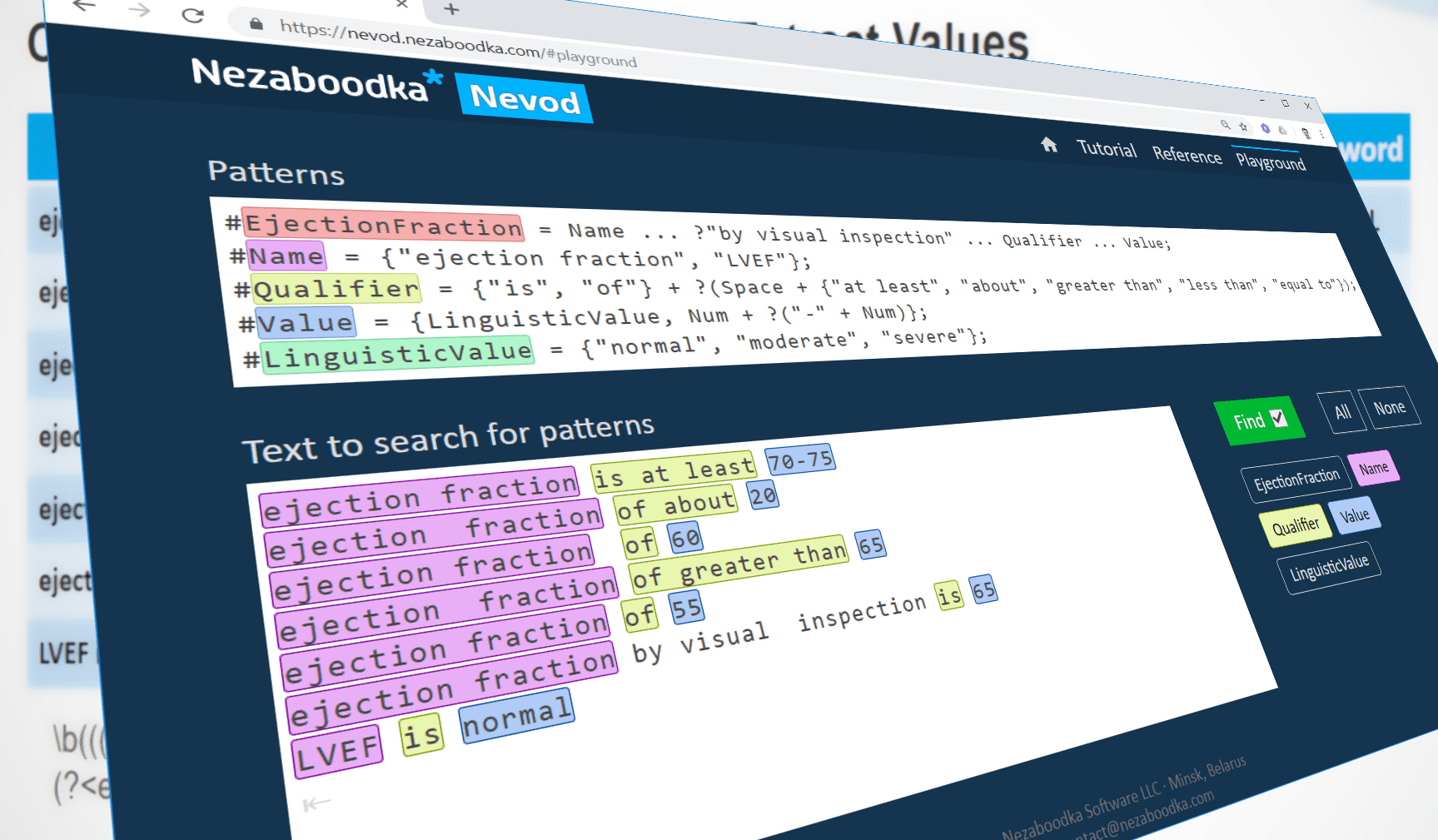
Here are Nevod patterns that detect ejection fraction values in text:
#EjectionFraction = Name ... ?"by visual inspection" ...
Qualifier ... Value;
#Name = {"ejection fraction", "LVEF"};
#Qualifier = {"is", "of"} + ?(Space + {"at least",
"about", "greater than", "less than", "equal to"});
#Value = {LinguisticValue, Num + ?("-" + Num)};
#LinguisticValue = {"normal", "moderate", "severe"};As you can see, Nevod patterns are named, operate over words (tokens), they can reference other patterns, and they are much more clear, so can be used by subject matter experts.
The pattern EjectionFraction is defined as the sequence with skipped spaces consisting of the pattern Name, optional text “by visual inspection” (the question mark makes it optional), the pattern Qualifier and the pattern Value.
The pattern Name is defined as variation of two text strings: “ejection fraction” and “LVEF”. The space between words in the first string matches any number of consecutive space symbols.
The pattern Qualifier is the sequence of one mandatory and one optional elements. The mandatory element is variation with two alternatives: “is” and “of”. The optional element is sequence consisting of Space and variation of qualifier supplements: “at least”, “about”, “greater than”, “less than”, “equal to”.
The pattern Value is variation of two alternatives: LinguisticValue and numeric token (Num) optionally followed by minus sign and another numeric token.
The pattern LinguisticValue is self-explanatory.
Let us take text examples from the above table to test our patterns:
ejection fraction is at least 70-75
ejection fraction of about 20
ejection fraction of 60
ejection fraction of greater than 65
ejection fraction of 55
ejection fraction by visual inspection is 65
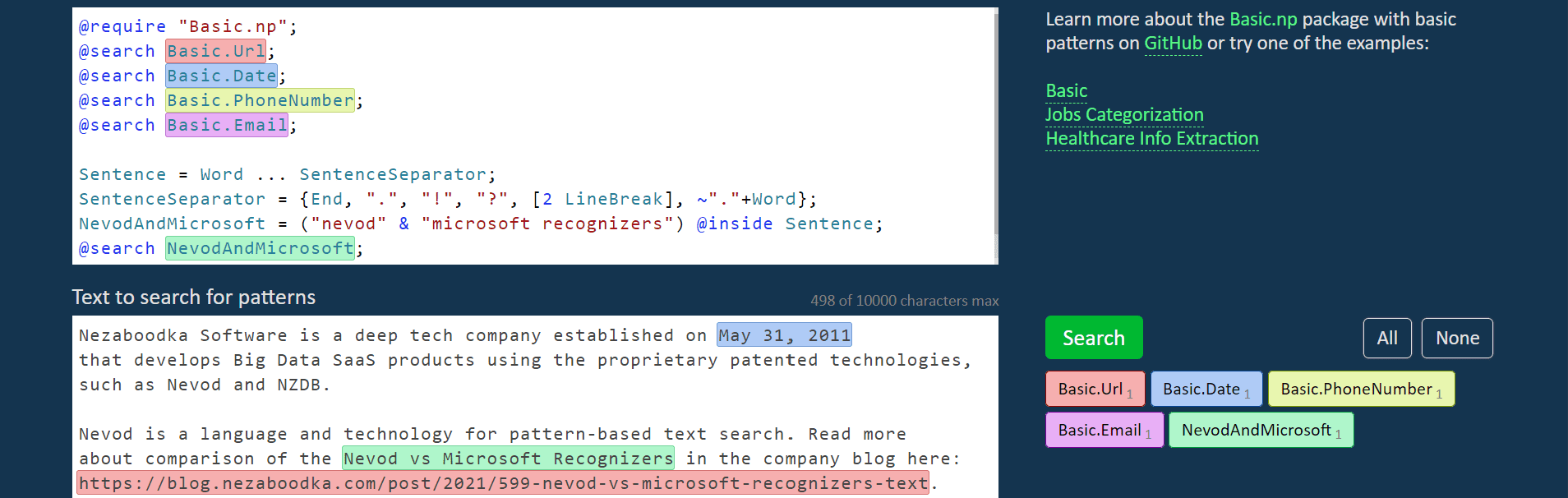
LVEF is normalYou can test them youself in the Nevod Playground. Click the Find button to get the result:

To show or hide pattern matches, click the color blocks on the right.
References
How to Use Text Analytics in Healthcare to Improve Outcomes — Why You Need More than NLP (Link).